

What is hyperconverging?
Hyperconverging is the latest hype: do things more efficiently with the resources that you have by cramming as many virtual machines on the same hypervisor. In theory this should allow you to mix and match various workloads to make the optimum use of your hypervisor (e.g. all cores used 100% of the time, overbooking your memory up to 200%, moving virtuals around like there is no tomorrow). Any cloud provider is hyperconverging their infrastructure and this has pros and cons. The pro is that it’s much cheaper to run many different workloads while the con clearly is when you encounter noisy neighbors. As Jeremy Cole said: “We are utilizing our virtual machines to the max. If you are on the same hypervisor as us, sorry!”
Apart from cloud providers, you could hyperconverge your infrastructure yourself. There are a few hardware/software vendors out there that will help you with that and at one of my previous employers we got a helping hand from one such vendor!
DIY hyperconverging
In our case the entire infrastructure was migrated to a new hyperconverged infrastructure where we would have multiple infrastructure clusters (read: four hypervisors in one chassis) in multiple data centers. Infra marked one of these DCs suitable for our customer facing projects as the peering was performed in that DC. The idea behind this new infrastructure is that the VM can basically run anywhere in your infrastructure and copied realtime to another hypervisor within the same cluster (read: chassis). This copy process (including memory) obviously required some (short) locking, but it even worked amazingly well. We even had some software running that would move around VMs to optimize the workloads and still retain some spare capacity. Magic!
Now there was an additional benefit to choose for this vendor: if a hypervisor would go down the same VM could be spun up immediately on another hypervisor, albeit without copying the memory contents. To be able to do this, the disks are synced to at least one other hypervisor. This means some cluster magic detects one of the hypervisors being down and automagically spins up the same VMs on another (available) hypervisor that contains the latest data of this VM. To spread the load among various hypervisors the replication factor of the disks is advised to be set to 2, where 2 means to be copied to (at least) two other hypervisors.
Hyperconverging Galera
Our Galera cluster consisted out of three Galera nodes and three asynchronous read replicas attached (see image below).
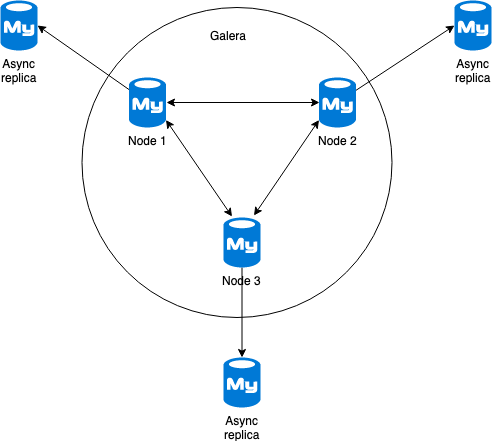
Galera cluster with read slaves
In this picture every Galera node stores every transaction in the GCache, InnoDB flushes the transaction to disk (ibdata*) and asynchronous replication dictates another write to the binlogs. That means that every transaction in our Galera node will already be stored three times on disk.
The hyperconverged cluster where we hosted Galera had the replication factor set to 2. That means every byte written to disk will be written to at least two other storage controllers (VMs), as shown in the image below. This write operation over the network is synchronously, so the filesystem has to wait until both controllers acknowledged the write. Latency of this write is negligible as the write is super fast and performed over a low latency network. The magic behind this synchronous disk replication is out of the scope for this blog post, but I can hint that a certain NoSQL database (named after some Greek mythology) is managing the storage layer.

Hyperconverge write amplification: every write to disk will be written three times!
This means that every write to disk in our Galera node will also be synced an additional two hypervisors. To make matters worse, due to semi-synchronous replication, all three nodes Galera perform the exact same operations at (almost) the exact same time!
1 transaction = 3 nodes (3 writes locally + 6 writes over the network) = 27 writes
As you can guess from the simple formula above: 9 writes are performed locally and 18 writes are performed over the network. As every write to disk is performed synchronously over the network, this write adds a bit more than negligible latency when it spawns 18 writes over the network at the same time. As 1 transaction to Galera can cause 18 synchronous writes over the network, imagine what latency you will encounter if you have a baseline of 200 transactions per second! And we’re not even counting the asynchronous replicas performing similar write operation again mere (milli)seconds later!
Galera managed to cope, but instability only happened on set intervals. We could trace these back to our so called stock-updates or pricing-updates: every half-an-hour stock levels were pushed from the warehouse database and every few hours new pricing information was also pushed via the enterprise service bus.
With more than a million products in the database these torrents of writes quickly caused disk latency in the entire hyperconverged cluster and we have seen the disk latency shoot up well beyond 80ms. This no longer affected the Galera cluster, but this was causing cluster wide issues on the distributed storage layer as well. And to make matters even worse: latency on the entire network was also shooting up.
Benchmarking semi-synchronously replicated hyperconverged clusters
At first nobody believed us, even when we showed the graphs to the vendor. This new infrastructure was so much more expensive than our old that it simply couldn’t be true. Only after conducting benchmarks, reproducing the latency on an empty test cluster, we were taken seriously. The benchmarks revealed that the write amplification saturated the network interfaces of the cluster and we worked with the vendor on seeking a solution to the problem. Even after upgrading the network (10G interface bonding, enabling jumbo frames, hypervisor tuning) we still found latency issues.
The issue with our hyperconverged cluster was that there was no (separate) internal network handling the inter-hypervisor network traffic. Of course we could now achieve the double amount of transactions, but that didn’t solve the underlying issue of also causing latency on other VMs and also causing latency on ingress and egress network of our applications.
Conclusion
We came to the conclusion that (semi-)synchronous replicated databases and hyperconverged infrastructures with high replication factors don’t match. Unfortunately this replication factor could only be set on cluster level and not on an individual VM level. Also the reasoning behind the synchronous disk replication did not make sense (see also my previous blog post) as Galera would wipe the disk contents anyway and in general it would take quite some time for the database to recover, so a quick failover would not happen anyway. That’s why we ran Galera+ProxySQL in the first place: to allow us to have a failover happen within seconds!
We also ran other (semi-)synchronous replicated databases: MongoDB, SOLR and Elasticsearch for example and each an everyone of them basically the same lack of need for disk replication.
The only option left was to migrate the Galera cluster back to our old hardware that, luckily/sadly, was still switched on. At the same time we started working on a migration to a real cloud vendor as they could offer us better performance without the risk of a single point of failure (e.g. single data center).
So what difference would a benchmark up front have made?
This only happened due to bad requirements without analyzing the workload that was supposed to be converged. We would have seen these issues before migrating to the new hyperconverged infrastructure if we would have benchmarked beforehand. We would have saved us from many instabilities, outages and post mortems. We might even have chosen a totally different setup or have chosen to split our workloads over multiple (smaller) hyperconverged clusters.
This is one of the background stories of my talk Benchmarking Should Never Be Optional on Wednesday 2nd of October 2019 at Percona Live Europe in Amsterdam.

In my talk I will feature a few cases why you should always benchmark your systems up front. It’s not only about database benchmarking, but in some cases even the entire system that requires benchmarking.





