When Percona released Percona XtraBackup 2.4.14 on May 1st 2019 they included a very important feature: streaming a backup to S3 and GCS using the xbcloud binary! My team implemented streaming our backups to shorten the total time for taking our backups. We found the streaming of our encrypted backups to GCS to be shorter than making them locally, but this is a subject for another blog post. The matter at hand in today’s post is that we found xbcloud was creating an enormous amount of small files. We found that xtrabackup creates files of 10MB by default. No matter what we tried, we couldn’t have the xbcould binary make larger files. In the end we managed to solve it with the (public) help of Percona!
TL;DR
The issue is that you can set the –read-buffer-size to change the size of the files created. However if you also encrypt your backup, this change gets lost. You then need to change the –encrypt-chunk-size to the same size as your –read-buffer-size and this will then create the changed file size.
The xbcloud problem
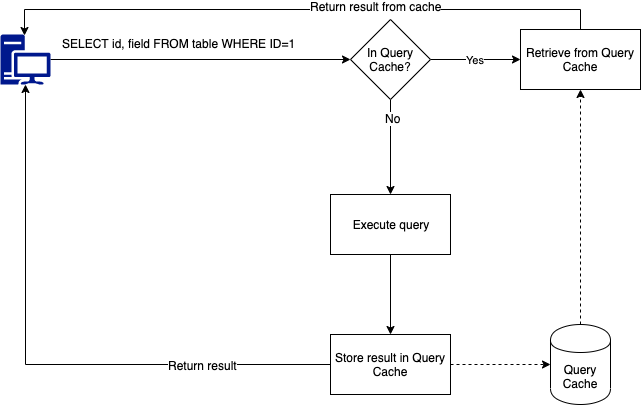
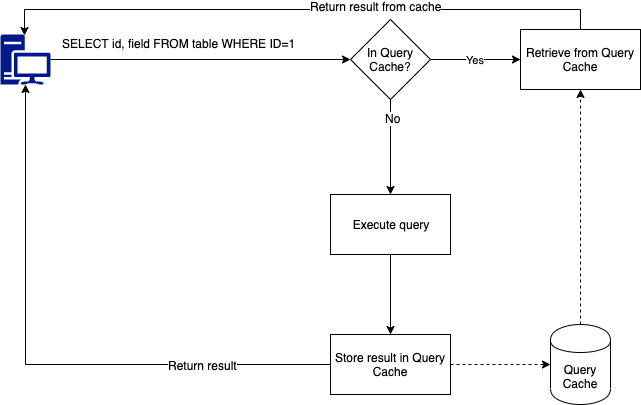
The problem is the construction of taking a backup. Xtrabackup will handle the MySQL part of the backup and pipes the backup to the xbstream and xbcloud binaries. The xbcloud binary will then stream the data to the backup bucket in 10MB chunks. This means that every time your backup stream reaches 10MB, a new 10MB file will be created in the bucket. The reasoning behind this is that if you hit a network error, not the whole file is lost and xbcloud can reupload the failed 10MB file and not the entire file. The number of retries by xbcloud is 3.
The issue we found is that large backups (8TB of data or larger) will create many many many files. Browsing through the GCS bucket shows you Google doesn’t even wish to estimate how many files there are unless you go to the final page. But a quick calculation says to me that an uncompressed and encrypted 1TB table should end up in at least 100,000 files. Unfortunately there are a couple of downsides attached to this.

Reliability of storage
When we look at the Cloud, we assume everything is stable and networking is always there. Google assumes GCS is reliable and only publishes numbers on the uptime of GCS (99.9%, so 3 nines). Let’s take this SLA and then assume there is a failure rate of 1 out of 1,000 file stores for storing a file in GCS. As xbcloud has 3 retry attempts, that means in theory we would have a chance of 1 out of 1,000,000,000 to get 3 consecutive errors. But when we get into the big numbers of files to upload, the failure rate of 800,000 files should be 0,0008 file stores. That means on our total batch we have a likelihood of 0.08% on a file storage failure. That doesn’t sound too bad, does it?
But it is far more likely that consecutive errors happen as there is a reason why the file storage failed in the first place. It could be the case a queue is full or the pod running the API that accepts the request is failing. So the likelihood of file storage failure is far bigger than what I just made up in the previous paragraph. Also the larger the numbers of total files get, the more likely you will end up with an error on storing a file. This error will then be propagated upwards by xbcloud to xtrabackup, which in turn make the entire backup fail. Retaking a backup to 8TB with a duration of 6 hours isn’t going to be my definition of fun.
And this is exactly what we encountered. Large backups tended to fail more often and even our automated retry mechanism on the backup would fail to produce a backup from time to time. With the help of support we have improved things by adding more retries for the file uploads. This lowered the chance of failed file stores, but it could still happen. So if we can lower the number of files we upload, we have less chance of a failed backup.
Cost of file operations
With cloud providers you pay mainly for storage used. However people also tend to forget you also have to pay for file operations. For instance with GCS uploading a file is a Class A operation and this costs $0.05 per 10,000 operations for normal storage and $0.10 per 10.000 operations for Nearline and Coldline storage. When we create a backup, we store it in a temporary bucket on Normal storage at first. We then stage the backup (test and verify) before moving it to a protected bucket that retains it for 30 days on Nearline. That means for a backup of 1TB (100,000 files), we actually do 100,000 Class A operations (store) and 100,000 Class B operations (get files to verify) in Normal and 100,000 Class A operations (moving to protected bucket) in Nearline storage. The cost for the operations alone in these various buckets are already $0.50, $0.04 and $1.00 per backup. This means the total costs for a 1TB backup are $1.54 for all bucket operations.
The costs for storing 1TB of data for a month in Nearline storage is $10.00. This means $1.54 costs for bucket operations make up a significant portion (about 13%) of the total costs for the backup. So if we can create larger files (chunks), we would be able to lower the total number of files and we would also be able to lower the total number of operations on these buckets.
Xtrabackup backup duration
Another potential issue of uploading 100,000 files is that there is extra overhead for transferring every individual file. The xbcloud binary is streaming data to the cloud provider as files one by one, so it has to wait for every file to complete and 10MB files are relatively small and quick to upload. Transferring these files is done via HTTPS, so there is also SSL overhead. You can make xbcloud upload files in parallel with the –parallel parameter, we configured 7 parallel streams and this makes it a bit better. However then all our 7 parallel streams will be waiting individually for files to complete during the transfer. We raised this concern, but were told file upload benchmarks showed there was no added benefit from uploading larger files than the default size. To me this felt very counter intuitive.
Why do we want a shorter backup duration? Remember we also stage our backups where we test and verify them? This process takes time as well and we’d rather have these backups as quickly as possible in our verified protected backup bucket. If a backup takes 8 hours to create, our backup verification process would also take at least 8 hours. This means we at most have a usable backup 16 hours after we initiated the backup. We then have to catch up 16 hours of transactions to get our recovered host to get back to 0 seconds replication lag. This means that if we can reduce the backup time to 4 hours, we would only have to catch up to 12 hours of transactions. This means we would get a 25% reduction on our time to recover for this specific database.
Fixing the file size problem
Naturally we reached out to our support and even with their help we couldn’t make it work. We knew it had to do with the –read-buffer-size parameter for xtrabackup, but increasing this to 100MB still created 10MB files inside the bucket. We suspected the cause to be the xbcloud binary creating the files was to blame as it contained a hard coded value. Our ticket remained open for over six months without a proper resolution.
We were also aware of a bug report (PXB-1877) on the public bugtracker of Percona that described our exact problem. In this bug we also actively contributed and commented. In late December 2021 the bug was kicked up once more and, as you can read in the bug report, the same results were shared there as well. In mid February it was kicked up again by the same person as he was having similar issues as we had: high cost and failed backups.
This time Marcelo Altmann responded once again that the –read-buffer-size could be used to control this. We responded we already tried that, but failed to see any result. But this time Marcelo asked us to share the full command. When we shared it he noticed we were using encryption via xtrabackup as well and told us to also set the –encrypt-chunk-size to the same size as –read-buffer-size. This fixed our issue and we’re happy ever after!
Conclusion
What probably caused the problem in the first place is that xtrabackup also pipes the stream through the xbcrypt binary. This then messes up the file size set in the –read-buffer-size. We implemented the change from external encryption to internal some time before streaming backups to a bucket. Also this behavior is not documented anywhere by Percona.
We now run a file size of 200MB each and this means we have a reduction of 20 times. Now all of a sudden Google finds showing file number estimates in our buckets a lot easier to do. We also definitely see a big improvement on large database clusters: backup duration dropped from 18,000 seconds to 13,000 seconds.

I do have to add that on small database clusters (smaller than 1TB) we do see increased backup duration. The example below shows this and this is about 10 minutes on a 18 minute backup.

We can’t see the improvement on cost effectiveness yet as our buckets are inside a shared project. However as we have achieved a reduction of 20, we expect the cost for bucket operations to become negligible compared to the storage costs.
What surprised us most were numerous claims that there wouldn’t be any benefit from increasing the file size. Perhaps the tests conducted by Percona were performed on hosts within the range between 100GB and 2TB of data. In this range you can probably see there is no real benefit from increasing these buffers, especially not to very large sizes.
One word of caution: don’t increase these two buffers too much. We toyed with various sizes and when we reached 1GB, it caused the xtrabackup chain to try to allocate an extra 2GB of memory for the buffers. Naturally the OOM killer dropped by to say hi. Not recommendable.